Speaker-Listener Label Propagation
The Speaker-listener Label Propagation Algorithm (SLPA) is a variation of the Label Propagation algorithm that is able to detect overlapping communities. The main difference between LPA and SLPA is that each node can only hold a single label in LPA while it is allowed to possess multiple labels in SLPA.
The algorithm begins with each vertex having its own unique label. It then iteratively records labels in a local accumulator based on specific speaking and listening rules. Then the post-processing of the record labels is applied. Finally, the algorithm removes the nested communities and outputs all the communities. Note that it is not guaranteed to produce the same results every time.
Specifications
CREATE QUERY tg_slpa (SET<STRING> v_type, SET<STRING> e_type, FLOAT threshold, INT max_iter, INT output_limit,
BOOL print_accum = TRUE, STRING file_path = "")Parameters
| Parameter | Description | Default |
|---|---|---|
|
The vertex types to use |
(empty set of strings) |
|
The edge types to use |
(empty set of strings) |
|
The threshold to drop a label |
0 |
|
The maximum number of iterations |
10 |
|
Whether to print the output in JSON format |
False |
|
The file to write the output to in CSV format |
(empty string) |
|
The maximum number of vertices to output. A value of |
0 |
Example
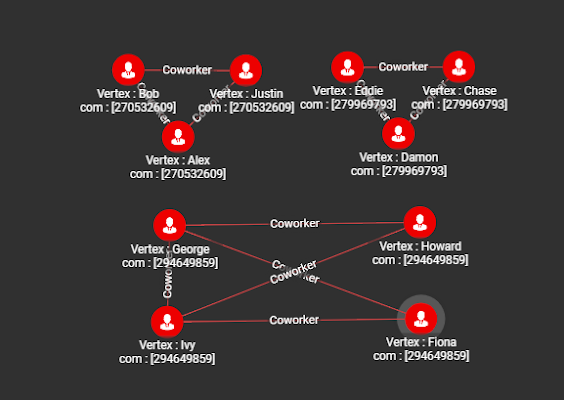
In the example below, we run the tg_slpa algorithm on the social10 graph. We set max_iter = 10 and threshold = 0.1.
# Use _ for default values
RUN QUERY (["Person"], ["Coworker"], _, _, _, _, _[
{
"@@COM": {
"Fiona": [294649859],
"Alex": [270532609],
"Damon": [279969793],
"Justin": [270532609],
"Eddie": [279969793],
"Chase": [279969793],
"Howard": [294649859],
"George": [294649859],
"Bob":[270532609],
"Ivy":[294649859]
}
}
]The result shows that each community has a unique community ID in the com attribute.