Continuous Availability Overview
Introduction
HA (High Availability) is a generic term used to describe a computer system which has been architected to deliver higher levels of operational performance through enhanced uptime and throughput than would be expected from a traditional single server node.
With Continuous Availability, TigerGraph goes beyond the standard scope and definition of High Availability by providing the following functionality:
-
Fault tolerance against loss of database server(s):
-
Automated recovery of most services in case of intra-cluster failure.
-
-
Full native HA support for user-facing applications:
-
Seamless automatic client reconnection to standby GSQL server and GraphStudio servers.
-
-
Failover to the replica node if the primary node is unavailable.
-
Improve RoI with additional replicas
-
Enhanced query throughput performance.
-
Increased concurrency for operational workloads.
-
In short, TigerGraph Continuous Availability not only provides the ability to keep a business application running without any noticeable downtime, but also delivers a higher return on investment.
Architecture Design
TigerGraph’s architecture design relies on active-active replication to keep multiple data copies in sync. This is transparent to the user. The underlying principles of uniform distribution of data are automatically applied no matter how many replicas are stored. Additionally, the placement of replicas is infrastructure-aware to tolerate hardware failures.
Continuous Availability is a production configuration that users can pick at cluster installation time. Users have flexibility to place replicas in specific availability zones or data centers based on their infrastructure requirements.
TigerGraph Continuous Availability design provides the following:
-
Throughput - Each replica is always up-to-date and handles its share of read requests. This provides higher query concurrency and throughput.
-
Automatic Failover - If a server goes offline for planned or unplanned reasons, TigerGraph’s HA design with Automatic Failover will reroute work to the replica nodes of that server, maintaining continuous operation.
-
System Resilience - Higher levels of replication provide more throughput and resilience.
Continuous Availability - Definitions
TigerGraph is based on an MPP architecture. All services are distributed uniformly across the cluster. This requires data to be distributed across the cluster. There are two key concepts in the cluster design:
-
Replication Factor: Replication factor is a characteristic of the cluster design that determines the number of copies of data that will be stored in the cluster. This is configurable at the time of installation.
-
Partitioning Factor: Partitioning factor is an internal TigerGraph characteristic of a TigerGraph cluster that determines how the data in the database will be distributed. Based on the nodes of the cluster size, TigerGraph will automatically pick a partitioning factor, taking into account the replication factor.
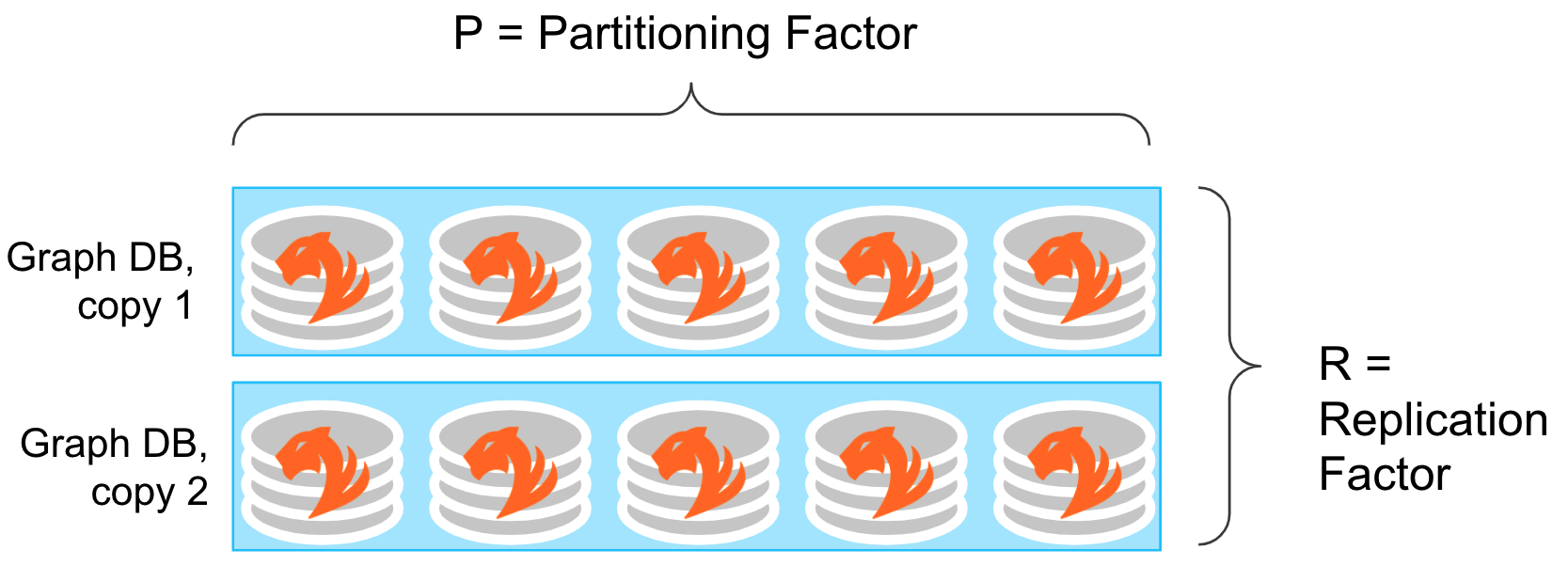
In short, a TigerGraph cluster can be seen as a combination of data spread across P partitions with multiple copies equal to the number of R replicas.
|
Some key cluster design considerations:
|
Continuous Availability - Data Operations
TigerGraph services are based on distributed leaderless architecture - all replicas are equal and can service both read and write requests. This is a key differentiation that ensures that no single node can be Single Point of Failure.
-
Write Operations: In order to keep all replicas in sync for full consistency of all data sets, all write operations are sent to all replicas synchronously by default. A write operation is considered complete only if all the replicas acknowledge that the writes are successful.
-
Read Operations: As all replicas are guaranteed to be in sync for all write operations, Read requests can be sent to any replica with no need to verify the data consistency with other replica copies. This optimizes the read performance for read-heavy analytical queries.
Example:
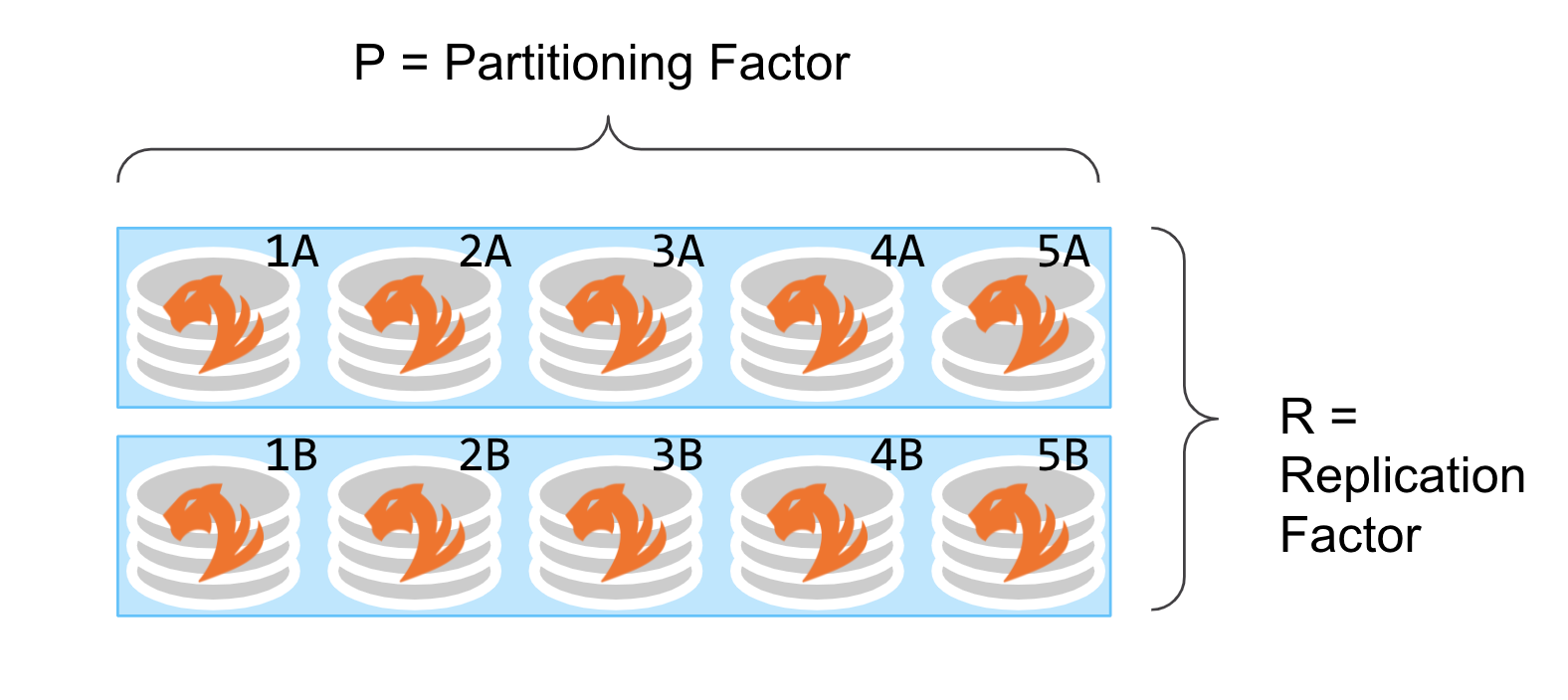
In the following example, the data sets in the cluster are spread across 5 partitions with 2 replicas of data sets i.e. Partitioning Factor of 5 and Replication Factor of 2.
-
All writes go to all replicas. For example, both 1A and 1B.
-
Reads can be from any one replica. For example, either 1A or 1B.
-
Distributed queries can read from a mix replicas. For example, {1A, 2B, 3B, 4A, 5B}.
Continuous Availability - Cluster failover operations
TigerGraph design ensures automatic failover for Continuous Availability. If a server goes down (hardware or software, planned or unplanned), incoming DB operations can continue. The requests are automatically routed around the unavailable server. The TigerGraph Database scheduler tracks in real time the availability of servers and routes the request to the right servers.
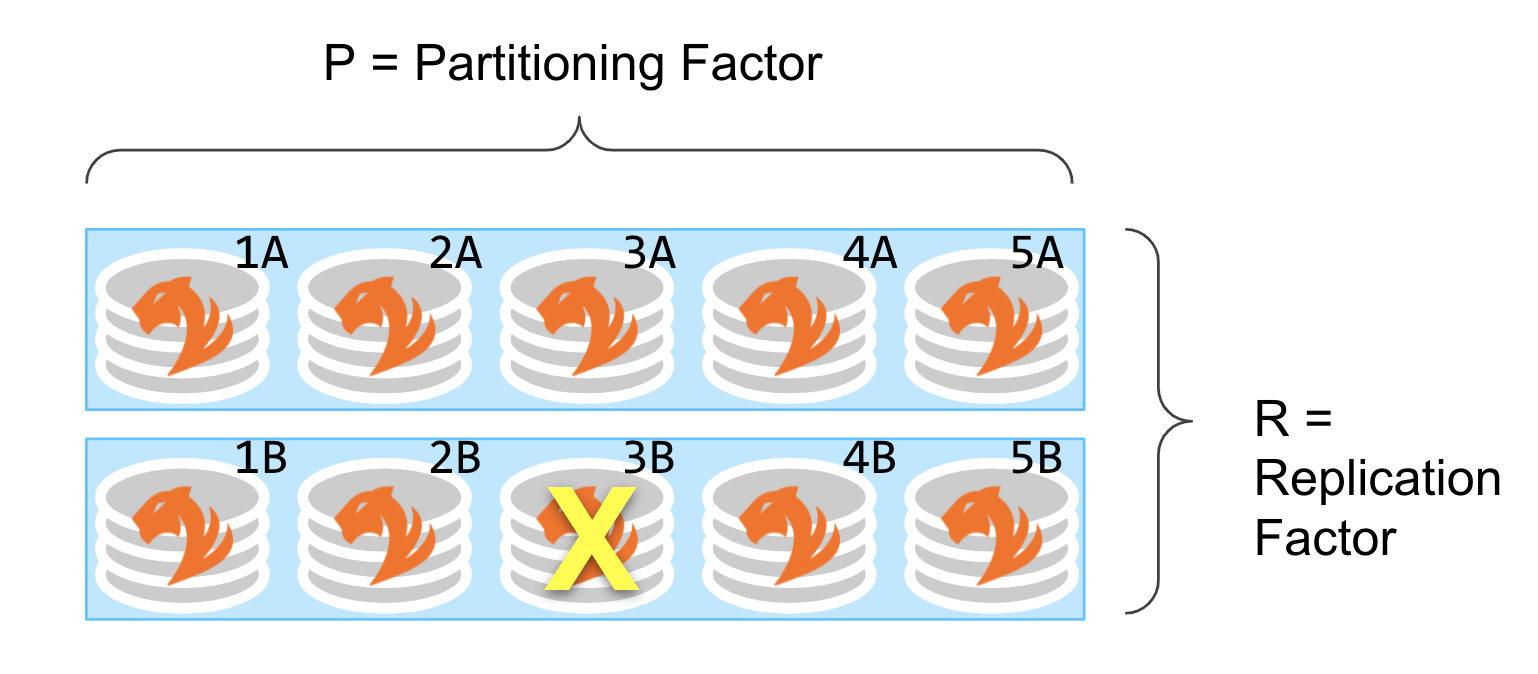
Example:
In the event of server failure:
-
If any single server is unavailable (expected or unexpected):
-
When it fails to respond after a certain number of tries, requests will automatically divert to another replica (e.g. 3B is unavailable, so use 3A).
-
If it fails in the middle of a transaction, that transaction might be aborted.
-
-
System continues to operate, with reduced throughput, until the server is restored.