Stream Data from Azure Blob Storage
You can create a data connector between TigerGraph’s internal Kafka server and your Azure Blob Storage (ABS) with a specified topic. The connector streams data from data sources in your ABS containers to TigerGraph’s internal Kafka cluster.
You can then create and run a loading job to load data from Kafka into the graph store using the Kafka loader.
1. Prerequisites
-
Your have an Azure storage account with access to the files you are streaming from.
2. Procedure
2.1. Specify connector configurations
The connector configurations provide the following information:
-
Connector class
-
Your Azure Blob Storage account credentials
-
Information on how to parse the source data
-
Mapping between connector and source file
2.1.1. Connector class
connector.class=com.tigergraph.kafka.connect.filesystem.azure.AzureBlobSourceConnectorThe connector class indicates what type of connector the configuration file is used to create.
Connector class is specified by the connector.class key.
For connecting to ABS, its value is
connector.class=com.tigergraph.kafka.connect.filesystem.azure.AzureBlobSourceConnector.
2.1.2. Storage account credentials
You have two options when providing credentials:
Shared key authentication requires you to provide your storage account name and account key.
You can find both the account name and account key on the Access Key tab of your storage account:
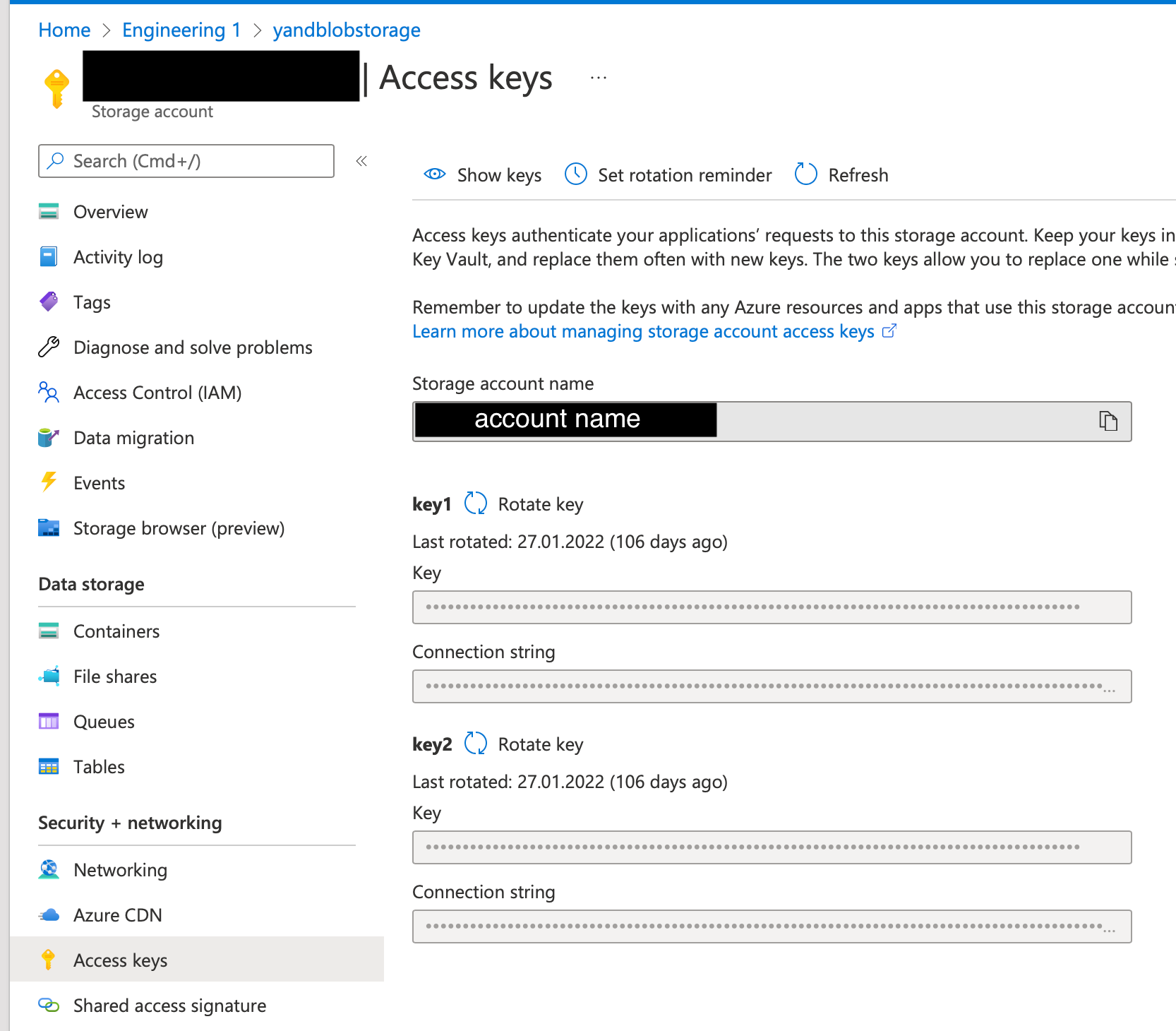
To specify the account name and key, use the following configuration.
Replace <account_name> with your account name and replace <account_key> with your account key:
file.reader.settings.fs.azure.account.key.<account_name>.dfs.core.windows.net="<account_key>"To use service principal authentication, you must first register your TigerGraph instance as an application and grant it access to your storage account.
Once the application is registered, you’ll need the following credentials:
-
CLIENT_ID -
CLIENT_SECRET -
TENANT_ID
Provide the credentials using the following configs:
file.reader.settings.fs.azure.account.oauth2.client.id="<client-ID>" file.reader.settings.fs.azure.account.oauth2.client.secret="<client-secret>" file.reader.settings.fs.azure.account.oauth2.client.endpoint="https://login.microsoftonline.com/<tenant-ID>/oauth2/token"
2.1.3. Other credentials
The connector uses Hadoop to connect to the Azure File system. The configurations below are required along with our recommended values:
file.reader.settings.fs.abfs.impl="org.apache.hadoop.fs.azurebfs.AzureBlobFileSystem" file.reader.settings.fs.abfss.impl="org.apache.hadoop.fs.azurebfs.SecureAzureBlobFileSystem" file.reader.settings.fs.AbstractFileSystem.abfs.impl="org.apache.hadoop.fs.azurebfs.Abfs" file.reader.settings.fs.AbstractFileSystem.abfss.impl="org.apache.hadoop.fs.azurebfs.Abfss"
2.1.4. Specify parsing rules
The streaming connector supports the following file types:
-
CSV files
-
JSON files. Each JSON object must be on a separate line.
-
directories
-
tar files
-
zip files
For URIs that point to directories and compressed files, the connector looks for all files inside the directory or the compressed file that match the file.regexp parameter.
By default, this includes both CSV and JSON files.
If you set file.recursive to true, the connector looks for files recursively.
The following parsing options are available:
| Name | Description | Default |
|---|---|---|
|
The regular expression to filter which files to read. The default value matches all files. |
|
|
Whether to retrieve files recursively if the URI points to a directory. |
|
|
The type of file reader to use.
The only supported value is |
|
|
The character that separates columns. This parameter does not affect JSON files. |
|
|
The explicit boundary markers for string tokens, either single or double quotation marks. This parameter does not affect JSON files. The parser will not treat separator characters found within a pair of quotation marks as a separator. Accepted values:
|
Empty string |
|
The default value for a column when its value is null. This parameter does not affect JSON files. |
Empty string |
|
The maximum number of lines to include in a single batch. |
|
|
End of line character. |
|
|
Whether the first line of the files is a header line. If the value is set to true, the first line of the file is ignored during data loading. If you are using JSON files, set this parameter to false. |
|
|
File type for archive files.
Setting the value of this configuration to
|
|
|
If a file has this extension, treat it as a tar file |
|
|
If a file has this extension, treat it as a zip file |
|
|
If a file has this extension, treat it as a gzip file |
|
|
If a file has this extension, treat it as a |
|
2.1.5. Map source file to connector
The below configurations are required:
| Name | Description | Default |
|---|---|---|
|
Name of the connector. |
None. Must be provided by the user. |
|
Name of the topic to create in Kafka. |
None. Must be provided by the user. |
|
The maximum number of tasks which can run in parallel. |
1 |
|
Number of partitions in the topic used by connector. This only affects newly created topics and is ignored if a topic already exists. |
1 |
|
The path(s) to the data files on Google Cloud Storage. The URI may point to a CSV file, a zip file, a gzip file, or a directory |
None. Must be provided by the user. |
URIs for files must be configured in the following way:
<protocol: abfss | abfs>://<container name>@<accountname>.dfs.core.windows.net/<path to the file>
For example:
abfss://person@yandblobstorage.dfs.core.windows.net/persondata.csv
2.1.6. Example
The following is an example configuration file:
connector.class=com.tigergraph.kafka.connect.filesystem.azure.AzureBlobSourceConnector file.reader.settings.fs.defaultFS="abfss://example_container@example_account.dfs.core.windows.net/" file.reader.settings.fs.azure.account.auth.type="OAuth" file.reader.settings.fs.azure.account.oauth.provider.type="org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider" file.reader.settings.fs.azure.account.oauth2.client.id="<example>" file.reader.settings.fs.azure.account.oauth2.client.secret="<example>" file.reader.settings.fs.azure.account.oauth2.client.endpoint="https://login.microsoftonline.com/<example>/oauth2/token" file.reader.settings.fs.abfs.impl="org.apache.hadoop.fs.azurebfs.AzureBlobFileSystem" file.reader.settings.fs.abfss.impl="org.apache.hadoop.fs.azurebfs.SecureAzureBlobFileSystem" file.reader.settings.fs.AbstractFileSystem.abfs.impl=""org.apache.hadoop.fs.azurebfs.Abfs file.reader.settings.fs.AbstractFileSystem.abfss.impl="org.apache.hadoop.fs.azurebfs.Abfss" mode=eof file.regexp=".*" file.recursive=true file.reader.type=text file.reader.batch.size=10000 file.reader.text.eol="\\n" file.reader.text.header=true file.reader.text.archive.type=auto file.reader.text.archive.extensions.tar=tar file.reader.text.archive.extensions.zip=zip file.reader.text.archive.extensions.gzip=tar.gz,tgz [azure_connector_person] name = azure-fs-person-demo-104 tasks.max=10 topic=azure-fs-person-demo-104 file.uris=abfss://example_container@example_account.dfs.core.windows.net/persondata.csv