Internal Architecture
As the world’s first and only Native Parallel Graph (NPG) system, TigerGraph is a complete, distributed, graph analytics platform supporting web-scale data analytics in real time. The TigerGraph NPG is built around both local storage and computation, supports real-time graph updates, and works like a parallel computation engine. These capabilities provide the following unique advantages:
-
Fast data loading speed to build graphs - able to load 50 to 150 GB of data per hour, per machine
-
Fast execution of parallel graph algorithms - able to traverse hundreds of million of vertices/edges per second per machine
-
Real-time updates and inserts using REST - able to stream 2B+ daily events in real-time to a graph with 100B+ vertices and 600B+ edges on a cluster of only 20 commodity machines
-
Ability to unify real-time analytics with large scale offline data processing - the first and only such system
See the Resources section of our main website www.tigergraph.com to find white papers and other technical reports about the TigerGraph system.
System Overview
The TigerGraph Platform runs on standard, commodity-grade Linux servers. The core components (GSE and GPE) are implemented in C++ for optimal performance. TigerGraph system is designed to fit into your existing environment with a minimum of fuss.
-
Data Sources : **The platform includes a flexible, high-performance data loader which can stream in tabular or semi-structured data, while the system is online.
-
Infrastructure : The platform is available for on-premises, cloud, or hybrid use.
-
Integration : **REST APIs are provided to integrate your TigerGraph with your existing enterprise data infrastructure and workflow.
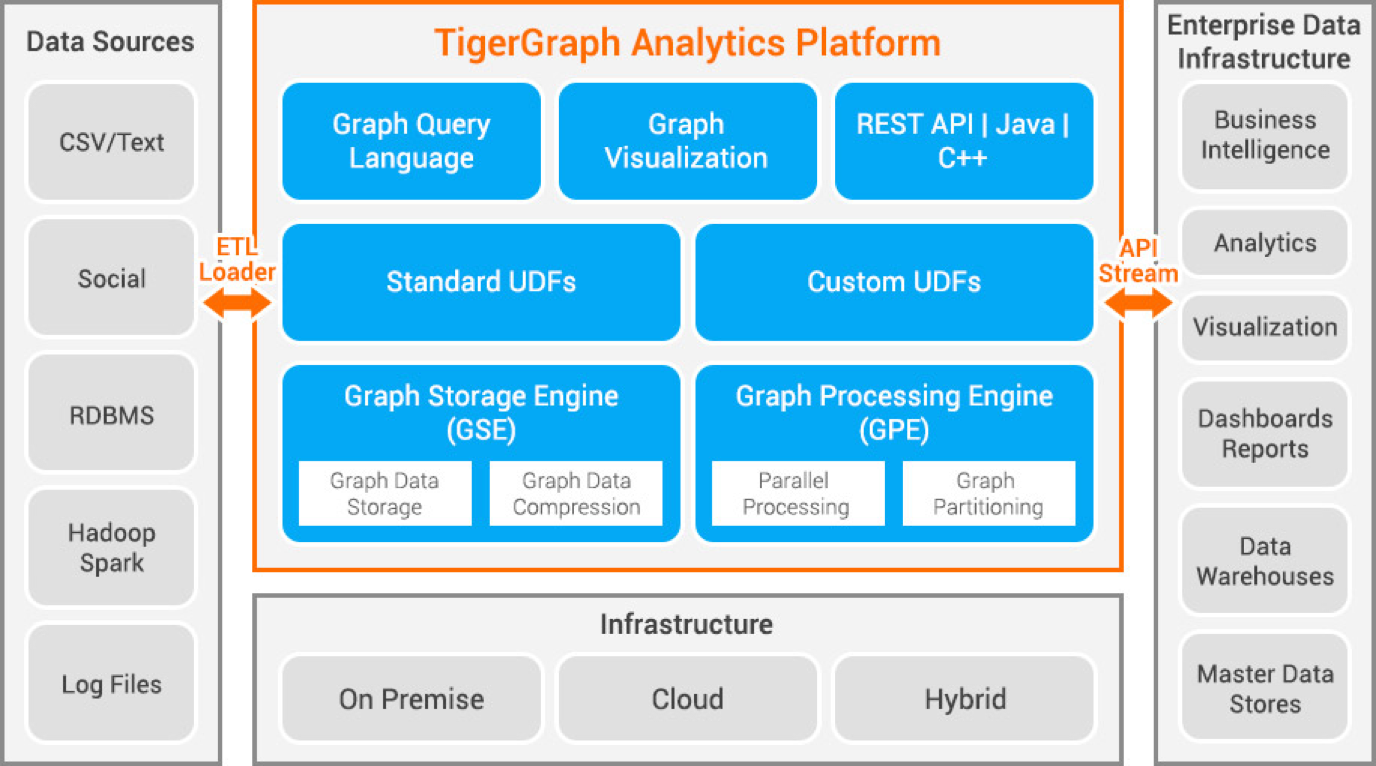
The figure below takes a closer look at the TigerGraph platform itself:
%20(2).png)
Within the TigerGraph system, a message-passing design is used to coordinate the activities of the components. RESTPP, an enhanced RESTful server, is central to the task management. Users can choose how they wish to interact with the system:
-
GSQL client. One TigerGraph instance can support multiple GSQL clients, on remote nodes.
-
GraphStudio - our graphical user interface, which provides most of the basic GSQL functionality, with a graphical and intuitive interface.
-
REST API. Enterprise applications which need to run the same queries many times can maximize their efficiency by communicating directly with RESTPP.
-
gAdmin is used for system adminstration.
Glossary
| Name | Refers to |
|---|---|
DDL |
Data Definition Language - a generic term for a set of commands used to define a database schema. The GSQL Language includes DDL commands. In GraphStudio, the Design Schema function. |
Dictionary (DICT) |
The shared storage space for storing metadata about the graph store’s configuration and state, including the catalog (graph schema, loading jobs, and queries). |
DML |
Data Manipulation Language - a generic term for a set of commands used to add, modify, and delete data from a database. Query commands are often considered a part of DML, even a pure query statement does not manipulate (change) the data. The GSQL Language includes full DML capability for query, add (insert), delete, and modify (update) commands. |
gadmin |
The system utility for configuring and managing the TigerGraph System. Analogous to mysqladmin. |
gbar |
Graph Backup and Restore. TigerGraph’s utility program for backing up and restoring system data. |
GPE |
Graph Processing Engine. The server component which accepts requests from the REST++ server for querying and updating the graph store and which returns data. |
Graph Store |
The component which logically and physically stores the graph data and provides access to the data in a fast and memory-efficient way. We use the term graph store to distinguish it from conventional graph databases. |
GraphStudio UI |
The browser-based User Interface that enables the user to interact with the TigerGraph system in a visual and intuitive way, as an alternative to the GSQL Shell. The GraphStudio UI includes the following components: Schema Designer, Data Mapper, Data Loader, Graph Explorer, and Query Editor. |
GSE |
Graph Storage Engine. The processing component which manages the Graph Store. |
GSQL |
The user program which interprets and executes graph processing operations, including (a) schema definition, (b) data loading, and (c) data updates, and (d) data queries. |
GSQL Language |
The language used to instruct and communicate with the GSQL program. |
GSQL Shell |
The interactive command shell which may be used when running the GSQL program. |
HA |
High Availability - a generic term describing a computer system which has been architected to a higher level of operational performance (e.g., throughput and uptime) than would be expected from a traditional single server node. |
IDS |
ID Service. A subcomponent of the GSE which translates between user (external) IDs for data objects and graph store (internal) IDs. |
Kafka |
A free open-source "high-throughput distributed messaging system" from the Apache Software Foundation. Our distributed system architecture is based on message passing/queuing. Kafka is automatically included during TigerGraph system installation as one implementation of messaging passing. https://kafka.apache.org/ |
MultiGraph |
A graph architecture and feature set which enables one global graph to be viewed as multiple logical subgraphs, each with its own set of user privileges. The subgraphs can overlap, meaning each subgraph can support both shared and private data. |
Native Parallel Graph |
An architecture and technology which provides for inherently highly-parallel and highly-scalable graph data storage and analytics. The use of vertex-level data+compute functionality is a key component of Native Parallel Graph design. |
Nginx |
A free, open-source, high-performance HTTP server and reverse proxy. Nginx is automatically included during TigerGraph system installation. https://nginx.org/en/ |
REST++ or RESTPP |
A server component which accepts RESTful requests from clients, validates the requests, invokes the GPE, and sends responses back to the client. Additionally, REST++ provides a zero-coding interface for users to define RESTful endpoints.REST++ offers easy-to-use APIs for customizing the logic of handling requests and processing responses. |
Single Sign-On (SSO) |
A user authentication service that permits a user to use one set of login credentials to access multiple applications. |
TigerGraph Platform |
The TigerGraph real-time graph data analytics software system. The TigerGraph Platform offers complete functionality for creating and managing a graph database and for performing data queries and analyses. The platform includes the Graph Store and GSE , GPE, REST++, GSQL, GraphStudio, plus some third-party components, such as Apache Kafka and Zookeeper. |
TigerGraph System |
The TigerGraph platform and its languages. Based on context, the term may also include additional optional TigerGraph components which have been installed. |
TS3 |
TigerGraph System Service State (TS3) is a TigerGraph sub-system which helps monitor the TigerGraph system. It serves as backend of TigerGraph Admin Portal. |
Zookeeper |
A free open-source program from the Apache Software Foundation, providing "a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services." Used for running the TigerGraph system on a cluster or other distributed system. Zookeeper is automatically included during TigerGraph system installation. https://zookeeper.apache.org/ |